At-bat Prediction
Ml Project
A neural network that predicts the outcome of a baseball at-bat based on a dataset of at-bat features.
← Back to ProjectsAt-Bat Outcome Prediction
With various xStats becoming more prevalent in baseball, it surprises me that they all use heuristic forms of prediction to determine the liklihood of certain outcomes. This project aims to move baseball into the modern landscape of machine learning by predicting at-bat outcomes using neural networks.
This project went through many iterations, 14 to be exact, all of which you can read about in the GitHub readme linked at the end, but this page will focus on the final and most successful iteration, 5.1.
Data
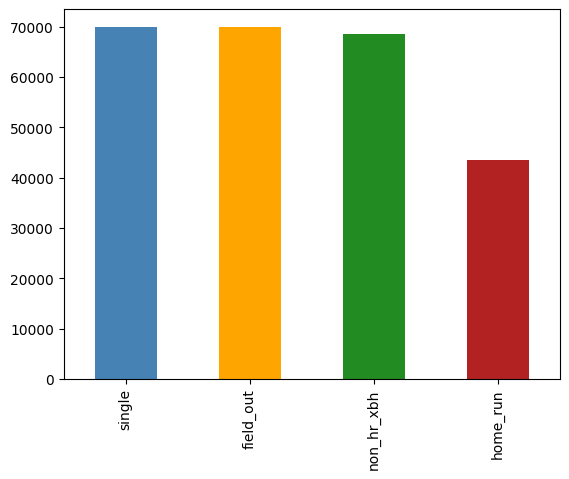
The dataset consists of outcomes for every at-bat from 2015 to 2022. This amounts to 900,000 rows. This data was acquired via another project of mine, Baseball Spider, which you can read about here. The data was pruned to roughly 250,000 rows, filtering out at-bats that did not put balls in play (eg. strikeouts) and ensuring that the target variables were evenly distributed. These variables were:
- Field Out
- Single
- Non-HR XBH (doubles and triples)
- Home Run
- Exit Velocity
- Z-axis Launch Angle
- XY-axis Launch Angle (horizontal angle)
- Pitch Velocity
- Pitcher Handedness
- Batter Handedness
- Strike Zone Location
- Release Spin Rate
- Batter Speed (in ft/s)
- Infield Alignment
- Outfield Alignment
Model
The model was built using PyTorch and the final iteration consisted of six hidden layers, with a max of 128 input nodes per layer, and a softmax output layer. The model was trained using the Adam optimizer and a learning rate of 3e-3 that was decayed using OneCycleLR. The loss function used was Cross Entropy Loss, which is standard for multi-class classification problems. Training look place over 1,000 epochs, with 80% of the data being used for trianing, 10% for testing, and 10% for validation. The model was trained on a single GPU, with a batch size of 1,028.
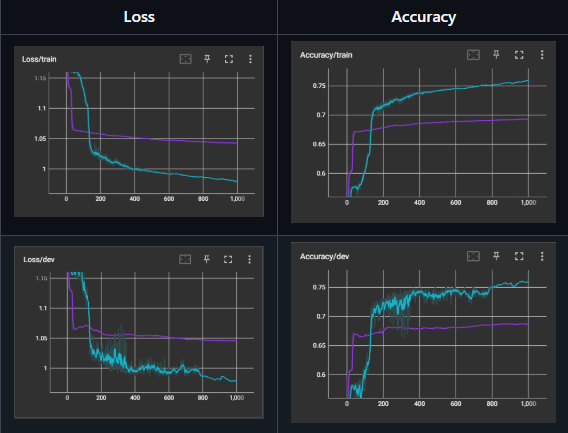
If you take a look at the graphs below, you can see that version 5.1 (the blue line) made huge strides compared to the previously best performing version (the purple line). The model was able to achieve an accuracy of 0.76, which is a huge improvement over the previous version, which was around 0.69. This was a huge step forward for the project and shows that the model is able to learn and adapt to the data.
IMAGE
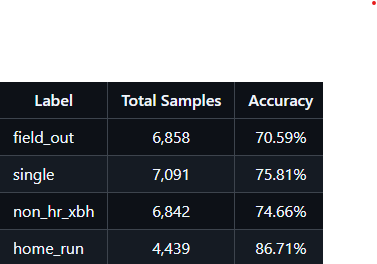
Examining the performance of specific outcomes, you can see that home runs were by far the best performing, at 0.87 accuracy, while all other outcomes ranged from the low to mid 0.70s. The reason for this should be fairly obvious, as home runs have a hard line of where they occur, while a groundball down the line could be an out, single, or xbh. I suspect the home run performance can be easily increased even higher by adding in park factors and wind conditions. As for the other outcomes, a more accurate XY-axis measurement of contact would help immensely; couple that with more accurate fielding alignments and fielder-specific information and those outcomes could see double digit improvments too.
Conclusion
This is a project I am very fond of, as it was the first real combination of two of my passions: baseball and machine learning. Not only that, but it showed great promise for how baseball can further be advanced using modern machine learning techniques. While I am not currently developing it, I consider this project "ongoing", because I do plan to return to it and see if version 6.0 has the potential to be a true game changer.