Throw Cast
Ml Project
A regular and multi-headed neural network that predict the likelihood of an out be recorded on a throw to first base.
← Back to ProjectsThrow Cast
The idea behind Throw Cast stems from a problem posed to me by a friend. What would be a new and better way to evaluate the arm of infielders? The core of my solution is to determine the likelihood they can record an out from a given position in the infield, compared to the consortium of other infielders at that position. This solution bears similarities to UZR, but with two key developments.
The first, is the incorporation of the quality of the first baseman. A throw is good if the first baseman fields it before the runner touches first, so it does not actually matter if the thrower bounces the ball, as long as the first baseman is capable of fielding bounced balls consistently. So the first step in modernizing this evaluation, is also building a first baseman model that determines the likelihood that a first baseman can field certain types of throws. Couple this model with a model of what sort of throw a fielder may produce from given locations on the infield and you can build the optimal defensive infield by finding infielder/first baseman combinations that maximize outs without compromising on offensive production.
The Data
The data for this project is synthetic. Rather than try and find all the key columns I might need in publicly available baseball statistics, I chose to use artificial datasets built around averages and distributions that were derived from real world information. This is by no means an ideal solution, but a perfectly effective starting point for testing the viability of an idea like this.
For the thrower model, I used seven features:
- distance_bucket - Buckets of distances from where the ball was fielded and first base, using Euclidean distance.
- start_outs - The number of outs when the play starts.
- out_importance - a derived metric that determines the value of the out based on game situation.
- runner_on_first/second/third - Three features to help understand unique fielder choices in these situations.
- thrower_position - The position they play on the field, to avoid scenarios where you might punish a second baseman fielding a ball up the middle because stronger armed shortstops usually do that.
For the receiver model, I used 11 features:
- All features from the thrower model, excluding thrower position.
- throw_velocity
- bounce_distance_bucket - The distance from first base the ball bounced, if it bounced.
- bounce_velocity - The velocity of the ball after it bounced.
- bounce_pos_x/y - The exact location the ball bounced, to account for difficulty to field these balls.
The Models
As previously mentioned, I built two models for this project. I decided on two because the goal should not necessarily be to evaluate a fielder's arm, but to evaluate their ability to get outs. This requires that we know who the fielder is throwing to, which in turn allows us to build a "map" of which fielder and first baseman combinations are the most optimal for getting the maximum number of outs.
Both of these models were built using neural networks. I chose neural networks for two main reasons. The first is that I wanted to take full advantage of the fact I had 20,000 rows of data to work with and something like a heuristic model often does not have a scaling factor as efficient as NNs. The second reason is the flexibility afforded by NNs. As new data potentially comes in and even new features, a neural net is particularly well-suited to quickly incorporate these new aspects and scale the model up to be even more accurate.
The Thrower Model
This model is a 9-layer, multi-headed network that predicts a thrower's exchange time, throw velocity, and likelihood that a given throw will bounce.
I evaluated this model using primarily the mean squared error for exchange time and velocity and I used cross entropy to evaluate the bounce chance.
Given the "quick and dirty" approach to building this model and several suboptimal design choices to speed up development, I am very pleased with how this model performed. As seen in the loss images below, the model was able to clearly improve its predictive power on all fronts, despite the high levels of variance introduced by using a multi-headed approach, rather than three separate models.
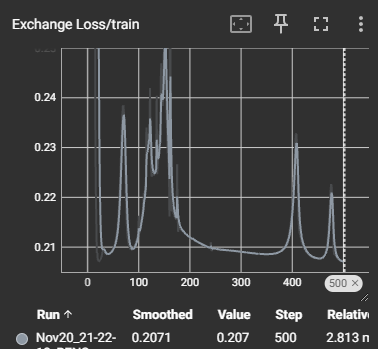
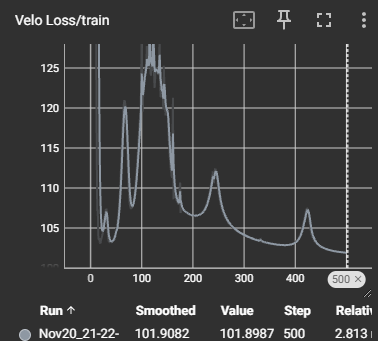
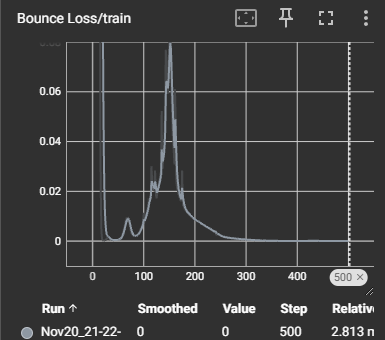
Given more time, this model could be vastly improved. I cut off the feature analysis and selection process earlier than typical, in order to have time to complete all steps and can already imagine several additions, such as redistributing the values and creating synthetic data, to boost the model. In addition, a more complete version of this model would certainly be at least two separate models, as I suspect some of the learning conflicted with one another (as seen by the erratic initial loss curves) and this is the sort of model that would benefit from much longer training times.
The Fielder Model
This model is a 7-layer neural net, with a softmax activation. It predicts whether or not a fielder will block an incoming bounced ball, based on the location of the ball, velocity at time of bounce, distance thrown from, and several other features. Like the previous model, it was evaluated using cross entropy.
This model is significantly more impressive than the thrower model, in my opinion. The main reason for this is because of how efficiently it was able to learn and improve despite being severely limited on data. I trained this model on bounced balls only, which restricted it to training on a little over 1,000 rows, but despite that it showed impressive learning and surprisingly little bias and overfitting.
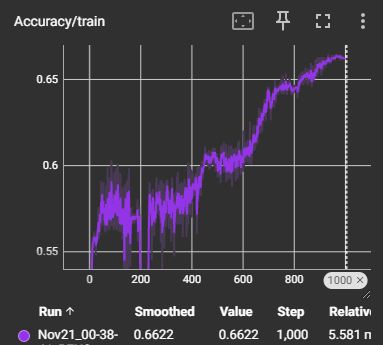
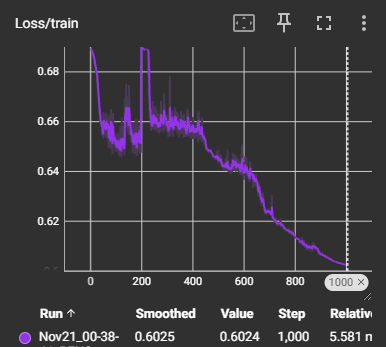
As seen in the above images, this model was able to achieve a 66% accuracy rating and an impressive decline in loss after only 1,000 epochs. I am also very confident that, given a little more tender loving care and maybe some more data, this model would easily eclipse 75% accuracy and beyond. The one downside of this model is it was more difficult to validate, as even with cross-validation, the tiny test and dev sets were often erratic in the results they gave. Even so, they both showed improvement overtime, suggesting a strong foundation to the model.
The Tool
To round out this project, I wanted to provide the models in a way that was more than just a report or spreadsheet, and feels like something that could be used as a dedicated tool for future data as well. That led me to creating a small single-page Flask app.

This app allows the user to:
- Set the speed of a batter and how close they are to first.
- Set the number of outs and baserunners.
- Set the location of both the thrower and receiver, by placing their respective dots on the baseball diamond in the bottom lefthand corner.
- Select any thrower and receiver.
- Then calculate the probabilities of an out being recorded, a bounced throw occurring, and a catch by the receiver.
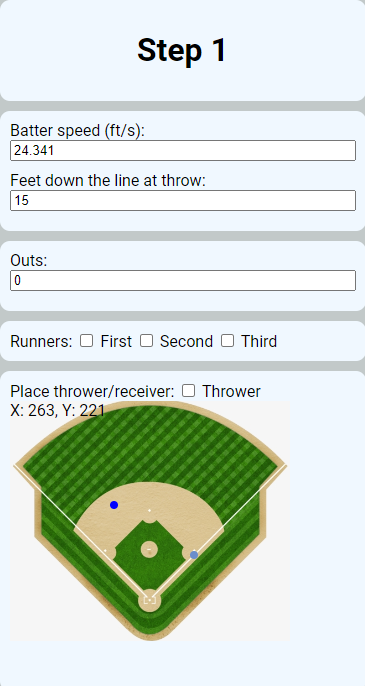
This puts a significant amount of the analytical control in the user's hands, as they can focus in on a very specific scenario or try many during "Step 1".
Then during step 2 they can actually review some of the key features of a given thrower or receiver, along with how they compare to the league at large.
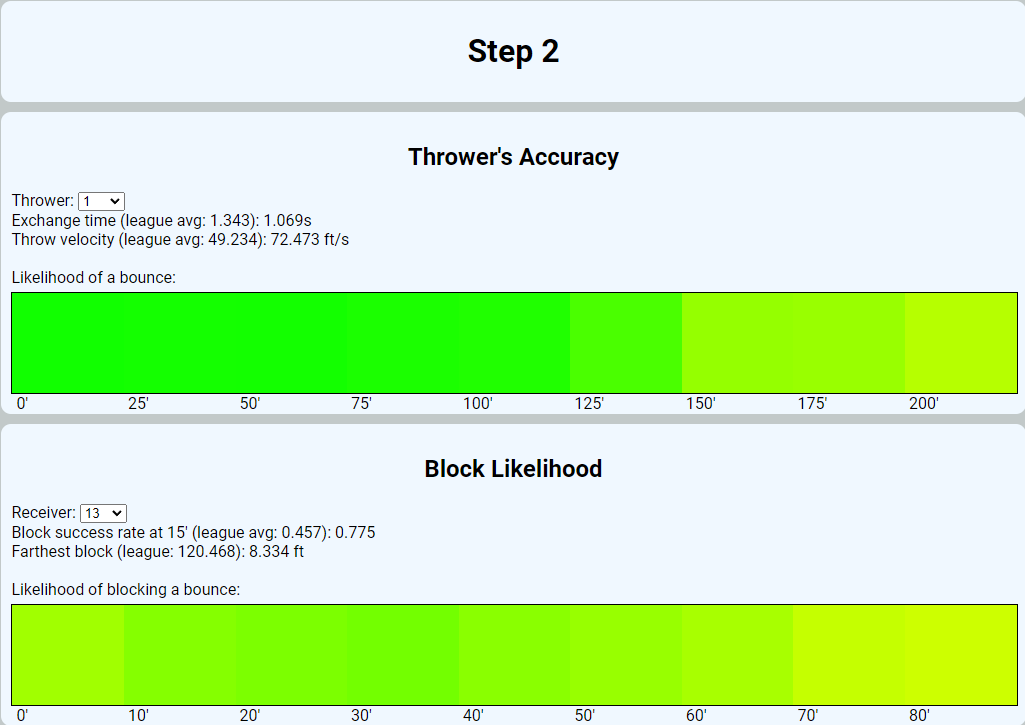

And finally, they can analyze how those two fielders pair with one another in the previously set scenario, how their performance compares to the average, and how likely that specific throw would be able to beat the pre-set runner to first base.
Final Thoughts
As I mentioned, while being very pleased with the achieved outcome, I can already see dozens of areas that could be improved to make this model even more effective. First, clarification on the data and what it represents would improve feature selection greatly. For example, does receiver_dist_from_1b represent the first baseman's position at the time of the throw or at the time of fielding? Another area I see huge potential for improvement in is additional features. Features such as "thrower_starting_position" and "hit_exit_velocity" would lay the groundwork to not only have a more improved image of a fielder's throwing ability, but also their range, reaction time, and ways to optimize fielder placement.
The three areas I would have loved spending more time on are: model tuning, feature analysis, and front-end improvements.
I was very drawn to the idea of analyzing specific game scenarios to see if certain levels of pressure altered a thrower's performance and, given more time, I would have certainly pivoted to it. But the area probably most neglected was model tuning. More time to tune hyperparameters, select my activation functions, experiment with model structures, and dig into the granular validation results could have almost certainly led to major improvements in both models.